


“Finite sampling errors” are uncertainties in the characterization of a statistical distribution caused by sampling a population only a finite number of times. The left-side graphs in the above images depict uncertainties in a cumulative distribution (CDF) inferred from a total of 10 and 100 sampled realizations taken from an exactly Weibull pseudo-random number generator having a shape parameter (also called Weibull modulus) of 4 and a median of 1; the exact plots are shown in orange. The wiggles and stair-stepping in the finite sample (black line) occur because too few realizations have been sampled to get an accurate characterization of the actual distribution from which the data were generated.
As detailed below, the plots on the right-hand-side are “Weibull transforms” of the ones on the left. A data set is demonstrated to be Weibull distributed if the plots on the right turn out to be straight lines. Finite sampling makes the Weibull lines kinked, so you will never get a perfectly straight line even though the data are (in this example) exactly Weibull distributed. The deviation from the exact (orange) Weibull line provides you with a sense of how the data for small samples sizes can jump around so dramatically that you really can’t rule out other possible distributions without getting more data.
Suppose that you convince 200 people to each take their own measurements to create their own finite-sized data set. Then their characterizations of the distribution would differ from each other by the amount of “jumping” you see in the black line. The gray lines show everyone’s data sets plotted together, so those serve as a visual depiction of finite-sampling uncertainty. As seen, if everyone is using a 10 point sample, their answers will differ from each other a lot. If everyone samples 100 points, then they will be in much greater agreement. If everyone samples 1000 points, the the plot would look like this:
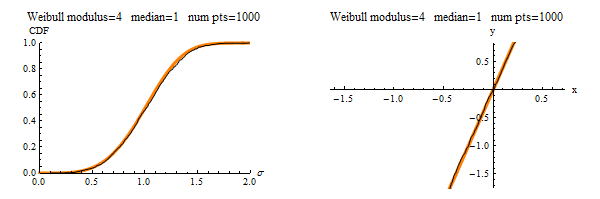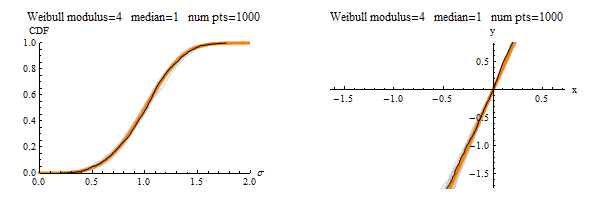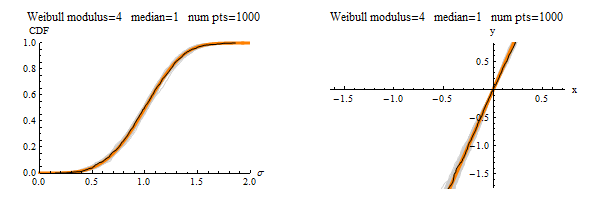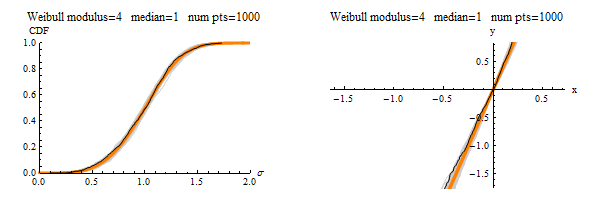
A little bit of wiggle is still visible, but at least everyone is using a large enough sample size to obtain fitted Weibull parameters that are closer the the right values used to generate the data in the first place!
Keep in mind that the data in these examples are exactly Weibull distributed. If you want to make plots like these yourself, first use math software to generate Weibull-distributed realizations. In Mathematica, for example, data that for the black lines in the 10 point plots (top of this posting) would be generated by
m = 4; median = 1; numPoints = 10;
dbn = WeibullDistribution[m, median Log[2]^(-1/m)];
data = Sort[RandomVariate[dbn, numPoints]]
cdf = Table[(i – 0.5)/numPoints, {i, numPoints}];
Note that the random data are sorted. The cdf values are paired with each sorted data value to create the plots on the left side of the graphs shown above. Note that the cdf values simply jump up by a height 1/N for each new data point, with the shift of 0.5 putting the cdf value in the middle of the jump. If P is the value of the cdf at a data point σ and if μ denotes the median for the entire finite sample, then the Weibull transforms of the cdf data are x=ln(σ/μ) and y=ln(ln(1/(1-P)))-ln(ln(2)). By design, these definitions make all of the data points pass exactly through the origin of the Weibull plot, facilitating data fitting to get the Weibull modulus from linear regression to y=mx.
Why should engineers care about this? A Weibull distribution is often used to characterize variables that, like a material’s tensile strength σ, must vary between 0 and ∞. The above plots use a Weibull modulus that might be typical of a granular composite, like concrete, so the plots are a sobering reminder that running only a few laboratory strength tests is not going to be adequate if you wish to protect the general public with a high degree of confidence. If possible, consult with a trained statistician before quoting Weibull properties that you have approximately inferred from finite samples — the proper way to report such properties is to also give a confidence interval.
